Mass - Cache Concepts
About Entity Component Systems
This is the first of a series of articles documenting what I know about the Unreal Mass framework.
Mass is an Unreal Engine module which implements an Entity Component System or ECS.
An entity component system is an architectural pattern where data related to objects, such as their velocity or position, is stored in a specific way in memory to speed up access to that data. The way an entity component system stores data in memory is influenced by the memory caching architecture of the CPU it is running on.
CPU Memory Caching
This is a very high-level view of caching. When the CPU wants to operate on a value (say to increment it or to add it to another value) that value first must be copied from main memory to the CPU.
If there was no memory caching (like we are back in 1980), every time the CPU needed to access a value it would have to be copied from main memory. To avoid this CPUs have cache memory, which is a small amount of memory physically either in the CPU or close by it. When a value is required by the CPU, the CPU checks to see if the value is already in the cache - if it is then it is copied from the cache to the CPU, if it is not it is copied from the memory to the CPU and also stored in the cache so it might be found if it is required again.
This image shows the cache layout on a Ryzen 8 core CPU:

From this we can see aspects of this specific memory architecture:
- there are 3 levels of cache L1, L2, L3 (some chips have more)
- the L1 cache consists of two separate parts the I Cache (instruction) and the D Cache (data). When considering entity component systems we only care about the data cache.
- each level is larger than the previous one - L1 is 32K, L2 is 512K, L3 is 32M
- each core has its own L1 and L2 cache
- the L3 cache is shared between all cores
When a value is required by the CPU:
- if it is in the L1 cache it is copied from L1, otherwise
- if it is in the L2 cache it is copied from L2, otherwise
- if it is in the L3 cache it is copied from L3, otherwise
- it is copied from memory
Each successive level of cache is slower to access than the previous one - it has a higher latency. To copy a value (ignoring the size of the value for now) to the CPU takes increasing time. Note that the timings vary from system to system depending on CPU type and memory speed, but the general trend is the same.
This image shows values for a 12 core Ryzen CPU:
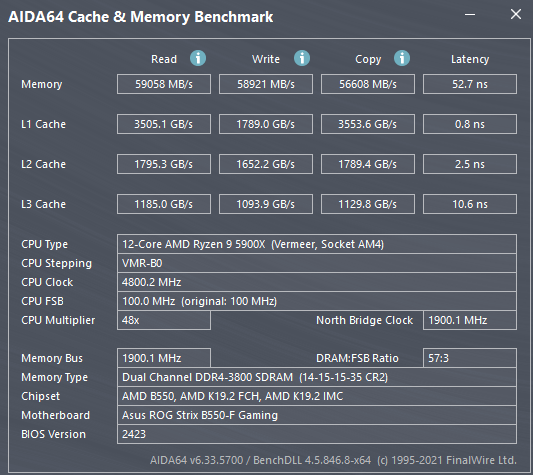
Fetching data from:
- L1 cache to CPU register - 4 cycles - 0.8ns
- L2 cache to CPU register - 12 cycles - 2.4ns
- L3 cache to CPU register - 52 cycles - 10.6ns
- memory to CPU register - 52.7 ns
So comparatively, fetching data from:
- L2 cache takes 3 times as long as from L1
- L3 cache takes 13 times as long as from L1
- memory takes 66 times as long as from L1
So in the extreme case a calculation could be done 66 times faster if all the required data was in the L1 cache as opposed to only being in memory.
Cache Lines
Values are not copied from main memory to cache memory one at a time. They are copied in cache lines. The size of a cache line depends on the CPU model but is typically 64 bytes. The CoreInfo program listed in references at the end of this page can be used to print the cache line size for your CPU.
Assuming a cache line size of 64 bytes, and an integer size of 4 bytes, one cache line can fit 16 integer values - this means that ideally we want to write a program so that each time we copy values from main memory into the L1 cache we move 16 integer values at a time. The first time we need one of the values we pay the 52.7ns cost of copying a cache line from main memory to the L1 cache, but for the remaining 15 integer values we only pay the 0.8ns for each value.
Entity Component Systems
An entity component system tries to group data which will be used into contiguous arrays so that every value used in a calculation is on a cache line with other values which will also be used, and also that no data is copied from main memory to the CPU which is not used.
A simple example
Say we have a Robot class and each instance of the Robot class robot has a position, a velocity, a size and an active flag like this:
struct FRobot
{
FVector Position; // 3x8 = 24 bytes
FVector Velocity; // 3x8 = 24 bytes
FVector Size; // 3x8 = 24 bytes
bool bActive; // 1 byte
};
We have a array of 1 million Robots, and we want to set the bActive property to true on every tick event. This code will do that:
namespace
{
struct FRobot
{
FVector Position; // 3x8 = 24 bytes
FVector Velocity; // 3x8 = 24 bytes
FVector Size; // 3x8 = 24 bytes
bool bActive;
};
TArray<FRobot> RobotArray;
void ActivateRobots()
{
TRACE_CPUPROFILER_EVENT_SCOPE(ActivateRobots)
{
for (FRobot& Robot : RobotArray)
{
Robot.bActive = true;
}
}
}
}
void AMyCharacter::BeginPlay()
{
Super::BeginPlay();
// initialize array
size_t N = 1024 * 1024;
RobotArray.AddDefaulted(N);
}
void AMyCharacter::Tick(float DeltaTime)
{
Super::Tick(DeltaTime);
ActivateRobots();
}
Using Unreal Insights we can see the ActivateRobots call takes 7.38ms (2400ms for 325 calls):
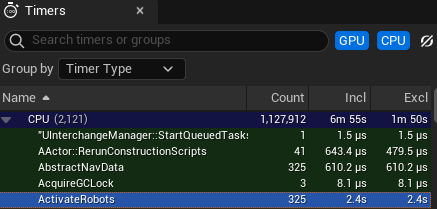
If we restructured the code to save each Robot property in a separate array, so we have one array for Ages, one for Positions etc. we have this:
namespace {
struct FRobots
{
TArray<FVector> Positions;
TArray<FVector> Velocities;
TArray<FVector> Sizes;
TArray<bool> Actives;
void AddDefaulted(const size_t N)
{
Positions.AddDefaulted(N);
Velocities.AddDefaulted(N);
Sizes.AddDefaulted(N);
Actives.AddDefaulted(N);
}
};
FRobots Robots;
void ActivateRobots_SOA()
{
TRACE_CPUPROFILER_EVENT_SCOPE(ActivateRobots_SOA)
{
for( bool& bActive : Robots.Actives)
{
bActive = true;
}
}
}
}
void AMyCharacter::BeginPlay()
{
Super::BeginPlay();
size_t N = 1024 * 1024;
Robots.AddDefaulted(N);
}
void AMyCharacter::Tick(float DeltaTime)
{
Super::Tick(DeltaTime);
ActivateRobots_SOA(Robots);
}
Here the _SOA appended to the name to distinguish the two approaches refers to Structure-of-Arrays. This terminology comes from the fact that the first approach uses an Array-of-Structures, the second approach as a single structure which contains the data in arrays.
Using Unreal Insights we can see the ActivateRobots_SOA call takes 1.18ms (385ms for 325 calls):
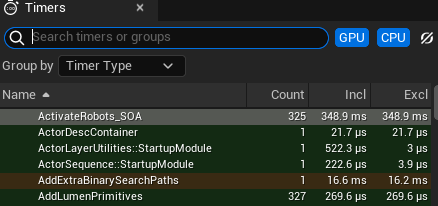
So by changing to storing the data in arrays we have made the function go 6 times faster. This is what the Mass entity component system tries to do for objects in Unreal Engine, it enables support for much larger numbers of objects than would be support by a strictly object oriented approach.
Data Types and Sizes
Storing data in arrays not only increases performance but it also saves memory:
struct FRobot
{
FVector Position; // 3x8 = 24 bytes
FVector Velocity; // 3x8 = 24 bytes
FVector Size; // 3x8 = 24 bytes
bool bActive;
};
When an array is filled with FRobot objects they align according to c++ alignment rules. The alignment of a struct is usually the maximum alignment of each of its members, so in this case the alignment alignof(FRobot) is alignof(FVector) which is 24 bytes - so we waste 23 bytes for each FRobot object.
Changing the bool to an int32 type has an observable effect:
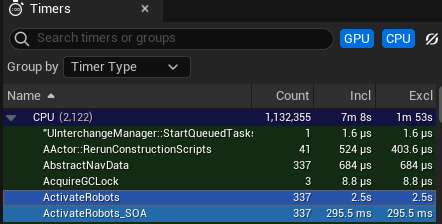
The ActivateRobots call changes takes 7.41ms (2500ms for 337 calls), an insignificant change from 7.38.
The ActivateRobots_SOA call changes takes 0.87ms (295ms for 337 calls), an 26% improvement from 1.18ms. This is probably due to the int32 property having better alignment than the single byte bool property.
Terminology
"cache locality" refers to the position of one thing with regard to another. If an algorithm uses two variables it is good if they are near each other in memory so when the first one is copied from main memory to a cache line, the second one will also be in the same cache line and will be copied as well. So when it is needed by the CPU it will already be in the cache.
Threading and False Sharing
Cache lines need to be considered when using threading to speed up tasks.
We can create a background task which counts the number of active robots like so:
class FCountActiveRobotsTask : public FNonAbandonableTask
{
public:
FCountActiveRobotsTask(const int32 InStart, const int32 InNum, int32& InCount )
: Start(InStart), Num(InNum), Count(InCount)
{
}
void DoWork()
{
for (int i = Start; i < Start + Num; ++i)
{
if (Robots.Actives[i])
{
Count++;
}
}
}
TStatId GetStatId() const { return TStatId(); }
private:
int32 Start;
int32 Num;
int32& Count;
};
We launch this background task for one thread only like this:
void Count_Robots_Background_Thread()
{
int32 Count = 0;
TRACE_CPUPROFILER_EVENT_SCOPE(Count_Robots_Background_Thread)
{
auto Task =
MakeUnique<FAsyncTask<FCountActiveRobotsTask>>( 0, Robots.Actives.Num(), Count );
if (Task)
{
Task->StartBackgroundTask();
Task->EnsureCompletion(true, true);
}
}
}
Comparing running on the main thread with doing the same task on a single background thread we see these timings:
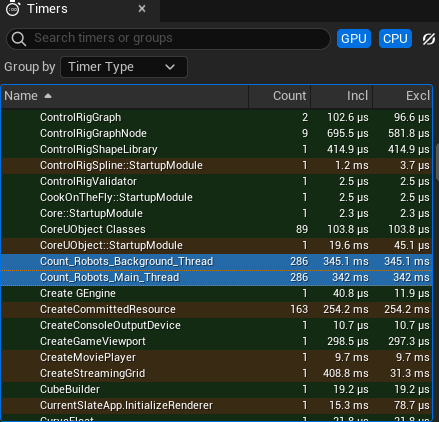
Running on the background thread is very slightly slower because of the overhead if starting and managing the thread.
We can change from running on one background thread to four like this:
void Count_Robots_Background_Threads()
{
int32 Count = 0;
TRACE_CPUPROFILER_EVENT_SCOPE(Count_Robots_Background_Threads)
{
constexpr int NumTasks = 4;
std::array<int32, NumTasks> Counts;
std::fill(Counts.begin(), Counts.end(), 0);
std::array< TUniquePtr< FAsyncTask<FCountActiveRobotsTask> >, NumTasks > Tasks;
int32 StepSize = Robots.Actives.Num() / NumTasks;
// create
for (int i = 0; i < NumTasks; ++i)
{
Tasks[i] =
MakeUnique<FAsyncTask<FCountActiveRobotsTask>>(StepSize * i, StepSize, Counts[i]);
}
// launch
for (int i = 0; i < NumTasks; ++i)
{
Tasks[i]->StartBackgroundTask();
}
// wait
for (int i = 0; i < NumTasks; ++i)
{
Tasks[i]->EnsureCompletion(true, true);
}
Count = std::accumulate(Counts.begin(), Counts.end(), 0);
}
}
In this code we:
- allocate 4 background task objects which will run on background threads
- divide the array of robots into 4 sections and pass each task the start and length of their section
- allocate an array of 4 int32 objects, each task accumulates their count into one element of this array
- after all the threads are finished we accumulate the 4 count objects into one value
Now we get these timings:
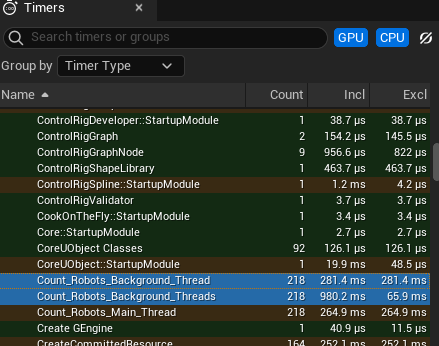
Running on four background threads takes 4 times longer than running on one. What is happening here is an issue of cache coherency and false sharing.
Here is the diagram of the cache layout on a Ryzen 8 core CPU again:
We see that each core has its own L1 and L2 cache. When a value is in main memory each CPU core that refers to that value has its own copy of that value in its L1 cache. Cache coherency is the mechanism by which changes to these cached values are synchronized - typically by using a protocol like MISE.
When one core changes a value in its cache, that value becomes invalid in every other core's cache which holds that value, and the next time one of those other cores accesses that value it is copied from the cache of the core which changed it. This mechanism make sure all the cores only ever see the same value, which make programming much easier, but it does mean that operations on the second core are stalled while value is retrieved from the core which changed it.
The MISE protocol which synchronizes values between cores does not work by copying individual values between core - it copies whole cache lines at a time.
Why we see a problem here, causing the multithreaded implementation to be so much slower, is not that we are updating the same value, but that the each thread is updating a value in the Counts array and all those values are on the same cache line. This problem is referred to as "false sharing" because while the threads are not actually sharing count values, synchronizing the core caches using whole cache lines makes it appear as if they were.
This problem can be fixed in a number of ways:
- we could give each task its own Count value to accumulate to accumulate into and only update the Count array once at the end
- we could make the Count array 16 times as large and have each thread use every 16th value - this would ensure that the used values are more 64 bytes apart so they are not on the cache line
- we could accumulate the values into property in a structure which was padded to be 64 bytes long, so that the values are not on the same cache line, like:
struct PaddedValue
{
int32 Value = 0;
char Padding[ 64-sizeof(int32)];
};
- we could accumulate the values into property in a structure which was aligned to 64 bytes long, so that the values are not on the same cache line, like:
struct alignas(64) AlignedValue
{
int32 Value = 0;
};
The code to accumulate into a local variable looks like this:
class FCountActiveRobotsTaskLocalCount : public FNonAbandonableTask
{
public:
FCountActiveRobotsTaskLocalCount(const int32 InStart, const int32 InNum, int32& InCount)
: Start(InStart), Num(InNum), Count(InCount)
{
}
void DoWork()
{
int32 LocalCount = 0;
for (int i = Start; i < Start + Num; ++i)
{
if (Robots.Actives[i])
{
LocalCount++;
}
}
Count = LocalCount;
}
TStatId GetStatId() const { return TStatId(); }
private:
int32 Start;
int32 Num;
int32& Count;
};
and the code to pad the Counts array and only use every 16th element looks like this:
void Count_Robots_Background_Threads_Padding()
{
int32 Count = 0;
TRACE_CPUPROFILER_EVENT_SCOPE(Count_Robots_Background_Threads_Padding)
{
constexpr int NumTasks = 4;
std::array<int32, NumTasks * 16 > Counts;
std::fill(Counts.begin(), Counts.end(), 0);
std::array< TUniquePtr< FAsyncTask<FCountActiveRobotsTask> >, NumTasks > Tasks;
int32 StepSize = Robots.Actives.Num() / NumTasks;
// create
for (int i = 0; i < NumTasks; ++i)
{
Tasks[i] =
MakeUnique<FAsyncTask<FCountActiveRobotsTask>>(StepSize*i, StepSize, Counts[i*16]);
}
// launch
for (int i = 0; i < NumTasks; ++i)
{
Tasks[i]->StartBackgroundTask();
}
// wait
for (int i = 0; i < NumTasks; ++i)
{
Tasks[i]->EnsureCompletion(true, true);
}
Count = std::accumulate(Counts.begin(), Counts.end(), 0);
}
}
This picture shows the results:
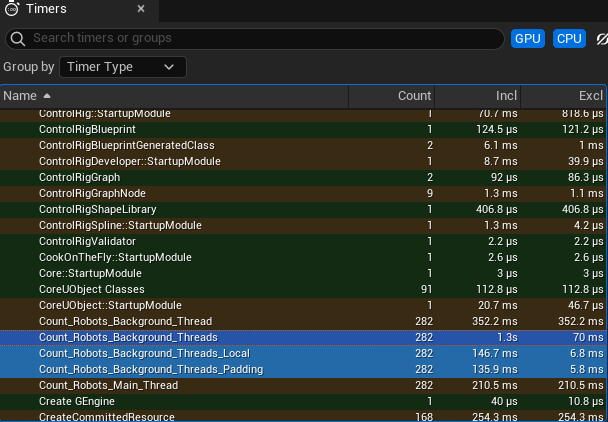
We can see that either using local variables or using padding eliminates the false sharing and reduces the time from 1,300ms to 140ms.
References
Mike Acton "Data-Oriented Design and C++"
CoreInfo
Writing Cache Friendly C++
Want Fast C++
Feedback
Please leave any feedback about this article here